Kettle-Grundlagen
Zielsetzung
Das Anwendungsspektrum vom OpenSource-Werkzeug zum Datenmanagement Kettle / Pentaho Data Integration reicht vom Kopieren einzelner Daten zwischen zwei Quellen bis zum professionellen "Data Warehousing". Für diesen Zweck bietet das Werkzeug eine mächtige Funktionalität und graphische Oberfläche. Die Nutzung des Werkzeugs wird unten anhand von praktischen Beispielen aus der Hochschulverwaltung vorgestellt.
Geschichte von Kettle
| Zeitpunkt |
Was passierte... |
| Sommer 2001 |
Der Belgier Matt Casters gründet eigenes Unternehmen als BI-Consultant |
| Ab 2003 |
Start der Arbeiten an Kettle. Ursprünglich war geplant, Kettle als KDE-Anwendung zu implementieren, daher der Name KDE Extraction, Transportation, Transformation and Loading Environment. |
| 2004 |
Kettle Version 1.2 mit SWT statt AWT. Das belgische Verkehrszentrum setzt Kettle ein |
| 2005 |
Kettle 2.0 wird veröffentlicht, mit Plugin-Architektur und SAP-Plugin. Matt Casters stellt Kettle unter OpenSource-Lizenz. In der ersten Woche hat Kettle 35.000 Downloads |
| 2006 |
Pentaho wechselt von Octopus zu Kettle, Matt Casters wird angestellt. Kettle wird zu PDI (Pentaho Data Integration) |
| 2010 |
Kettle / PDI 4.0 Release |
| 2015 | Pentaho wurde von Hitachi Data Systems aufgekauft. |
| 2022 | Der Kettle Fork "hop" wird ein Top-Level Produkt der Apache Foundation. |
Wir sehen dass die Software eine "bewegte" Geschichte hat. Durch die ganzen Namensänderungen bleiben wir erstmal beim Namen "kettle". Weitere Details siehe Wikipedia-Eintrag.
Alternativen
Eine Übersicht finden Sie auf Wikipedia:

Kommerzielle Produkte im DWH-Bereich:
- IBM InfoSphere
- Informatica
OSS-Tools
- Talend
- PDI / Kettle
- Octopus
Installation und Einrichtung
Voraussetzungen
- Kettle läuft unter Windows und Linux bzw. anderen Systemen mit Java Runtime
- Derzeit wird Java 8 oder Java 17 vorausgesetzt, und zwar nur genau diese Versionen. Ältere Java Versionen und Java 11 werden derzeit nicht unterstützt.
Entgegen der Dokumentation funktioniert auch ein Open Source Java, z.B. openjdk, Sie müssen nicht Oracle Java nehmen. Zur Installation von OpenJDK siehe unsere Java-Installationsanleitung.
Download und Installation
Kettle oder PDI (Pentaho Date Integration) steht unter Apache License V.2.0.
- Es gibt einen Community Bereich bei Hitachi, wo Sie die Software nach Registrierung herunterladen können: https://community.hitachivantara.com/home
- Einen Download ohne Registrierung erhalten Sie auch
- auf Sourceforge: https://sourceforge.net/projects/pentaho/
- auf github: https://github.com/pentaho/pentaho-kettle (nur Quellcode)
Start nach der Installation
Kettle beinhaltet die Anwendung Spoon (graphische Entwicklungsumgebung), sowie die Anwendungen kitchen und pan. Letztere erlauben den scriptgesteuerten Aufruf von Jobs bzw. Transformationen. Die Anwendung carte ermöglicht den Remote-Einsatz von Kettle.
Am besten beginnen Sie mit der graphischen Entwicklungsumgebung "Spoon".
Allgemeines zu Spoon
Das Kommandozeilen-Script "spoon.sh" bzw. "spoon.bat" liegt im obersten Verzeichnis der Auslieferung. Wenn Java 8 oder 17 installiert ist, reicht es die Datei mit Doppelklick zu starten. Aus der Kommandozeile starten Sie mit
spoon.bat /norep
oder
spoon.sh /norep
"/norep" setzt den Parameter, dass Kettle nicht nach einen Repository Server sucht.
Spoon Besonderheiten für Linux
Unter Linux sucht Spoon zunächst nach einer passenden Java-Runtime: entweder Sie setzen die Variable JAVA_HOME / JRE_HOME, oder Sie installieren oberhalb von spoon.sh im Verzeichnis java eine passende runtime. Wenn Sie nur eine spezielle Runtime verwenden wollen, setzen Sie z.B.
PENTAHO_JAVA_HOME=/usr/lib/java export PENTAHO_JAVA_HOME
Wenn sie nach dem Start die Meldung bekommen:

Dann müssen Sie zunächst das Paket libwebkitgtk installieren. Z.B. unter Ubuntu Linux:
apt-get install libwebkitgtk-1.0-0
Danach starten Sie Spoon neu.
Hinweis: Spoon stürzt unter manchen Linux-Versionen ab sobald man auf "Preview" klickt oder eine Transformation starten will.
- Ursache
- vermutlich ist die SWT Bibliothek in Spoon nicht kompatibel mit dem Betriebssystem.
- Lösung
- Besorgen Sie sich eine swt-Datei z.B. aus dem aktuellen Eclipse-Paket. Es liegt im Ordner "plugins", ermittelbar dort mit
ls org.eclipse.swt*jar
Diese Dateien kopiert man ins Spoon Verzeichnis nach
libswt/linux
(jeweils x86 und x86_64), die alten Dateien benennt man um nach swt.old. Danach startet man Spoon neu.
Spoon unter Windows
Unter Windows installieren Sie zunächst Java, und setzen dann in der Systemsteuerung die Umgebungsvariable JAVA_HOME auf den Pfad, wo Java installiert ist, z.B.
C:\Program Files\Java\jre1.8.0_45
Probieren Sie den Start mit Doppelklick auf die Datei spoon.bat. Bei Startproblemen unter Windows öffnen Sie eine DOS-Box ("Eingabeaufforderung") und gehen mit cd in das Verzeichnis, wo Kettle installiert ist (z.B. C:\Users\superx\pdi-ce-7.0.0.0-25\data-integration ). Führen Sie in der DOS Box das Kommando aus:
set JAVA_HOME=C:\Program Files\Java\jre1.8.0_45
Editieren Sie dann die Datei spoon.bat und ersetzen Sie den Aufruf "javaw" durch "java". Achtung: das geht nicht mit Windows Notepad, weil es die Unix Zeilenumbrüche nicht versteht, Sie müssen einen alternativen Editor. z. B. Windows WordPad nehmen und starten Sie das Script
spoondebug.bat
Beantworten Sie alle Fragen mit "Y", am Ende wird eine Datei
SpoonDebug.txt
geschrieben, der Sie diagnostische Meldungen entnehmen können. Wenn z.B. das RAM nicht ausreicht, müssen Sie die Datei spoon.bat editieren, und den Passus "-Xmx2048m" ersetzen z.B. durch "-Xmx1024m". Weitere Hilfen bei Startproblemen siehe den FAQ.
Spoon Einstellungen
Als erstes sollten Sie die Sprachumgebung von Spoon einstellen: Im Menü Tools -> Options wählen Sie im Reiter "UI Settings" die deutsche Umgebung:

Achten Sie darauf, daß Sie bei "Alternative Language" English angeben, damit Menüs, die noch nicht übersetzt sind, in Englisch angezeigt werden.
Kettle und Spoon in der Praxis
Vokabular
Zunächst: Kettle unterscheidet Jobs und Transformationen. Jobs sind Sammlungen von Aktionen in einer definierbaren Reihenfolge, und mit Kettle ausführbar. Transformationen sind die Bausteine von Jobs, und dienen der Datenverarbeitung. Innerhalb von Jobs und Transformationen sind die einzelnen Aktionen sog. "Steps", deren Reihenfolge wiederum durch Verknüpfungen ("hops") organisiert wird.
Jobs und Transformationen werden lokal im XML Format gespeichert, die Endung ist jeweils "*.kjb" fürs Jobs und "*.ktr" für Transformationen.
Hallo Welt
Hallo Welt Design
Unsere Beispiel-Transformation erzeugt 10 Zeilen "Hallo Welt", die am Bildschirm angezeigt werden, sowie als Datei gespeichert werden. Das Beispiel soll die Grundprinzipien von Spoon veranschaulichen.
Starten Sie Spoon, und machen Sie einen Doppelklick auf "Transformations", und wählen Sie unterhalb von "Input" den Schritt "Generate Rows". Ziehen Sie die Zeile in den Entwurfsbereich. Machen Sie dann einen Doppelklick auf das Icon. Danach konfigurieren Sie den Schritt:

Das Icon ändert sich dann im Entwurfsbereich:

Danach ziehen Sie unter "Flow" den Schritt "Dummy" in den Entwurfsbereich. Dann markieren Sie den Schritt "Erzeuge 10 Nachrichten", und halten die Shift-Taste gedrückt. Dann ziehen Sie von dort einen Pfeil zum Dummy-Schritt:

Dann speichern Sie die Transformation mit dem Namen "hallo_welt.ktr" und markieren im linken Menü die Transformation, und drücken die rechte Maustaste. Sie können dann einen Namen und einen Beschreibungstext vergeben:

Dann markieren Sie den Dummy-Step, und klicken Sie auf das Preview Icon:
![]()
Es erscheint ein Dialog:

Klicken Sie hier auf "Quick Launch". Es erscheint das Ergebnis:

Hallo Welt Protokollierung
Machen Sie einen Doppelklick auf den Schritt "Erzeuge 10 Nachrichten", und erhöhen Sie das Limit von 10 auf 10.000. Klicken Sie dann auf "OK", und zeigen Sie über das Menü "View"-> "Execution Results" die Ausgabe an. Wählen Sie dann die Registerkarte "Logging". Klicken Sie dann in der Symbolleiste auf das "Run"-Icon:
![]()
Wählen Sie bei "Log Level" den "Row level":

Dann klicken Sie unten auf "Launch". Die Transformation wird gestartet, und im Register Logging sehen Sie ein Protokoll:

Neben dem Protokoll können Sie auch eine Ausführungsstatistik aufrufen:
Hallo Welt Dateiausgabe
Speichern Sie obige Transformation als Datei "hallo_welt_dateiausgabe.ktr" und löschen Sie den Dummy-Schritt im Entwurfsbereich. Wählen Sie dann unter Output den Schritt "Text file output", und ziehen Sie den Schritt in den Entwurfsbereich. Danach können Sie den Schritt "Erzeuge 10 Nachrichten" damit verbinden. Machen Sie dann einen Doppelklick auf den Text File Output Schritt, und vergeben Sie den Namen "Hallo Welt Ausgabe".

Bei den Eigenschaften des Schrittes Ausgabe können Sie nun einen Dateinamen angeben. Wählen Sie hier keinen absoluten Pfad, sondern drücken Sie im Feld die Taste STRG-Leerzeichen. Es erscheint eine Auswahlliste, wo Sie den Pfad
${Internal.Transformation.Filename.Directory}
auswählen. Ergänzen Sie dann noch den Dateinamen "hallo_welt":

Hallo Welt in Excel
Für den Export nach Excel erzeugen Sie eine neue Transformation hallo_welt_dateiausgabe_excel.ktr

Die Eigenschaften des Excel Exports sind selbsterklärend.
Hallo Welt als Job
Wählen Sie in Spoon im Menü "New" den Eintrag "Job". Drücken Sie dann CTRL-j, um die Eigenschaften des Jobs zu definieren:

Im Entwurfsbereich ziehen Sie zunächst unter "General" das Icon "Start" herein. Ziehen Sie dann unter "General" das Icon "Transformation" in den Entwurfsbereich, und verbinden Sie beide Schritte:

In den Eigenschaften der Transformation wählen Sie im Feld "Transformation Filename" wieder STRG-Leerzeichen, und wählen die Variable "${Internal.Job.Filename.Directory}" und als Unterverzeichnis den Dateinamen der Transformation:

Sie müssen den Job dann im gleichen Verzeichnis wie die Transformation speichern. Mit dem "Run"-Icon können Sie den Job testen.
Hallo Welt im Batch-Modus
Um den Hallo-Welt-Job über die Kommandozeile aufzurufen, wählen Sie folgenden Befehl:
kitchen.sh /file:<<Absoluter Pfad zu Datei>>hallo_welt.kjb /norep
Damit wird der Job über die Kommandozeile ausgeführt. Der Schalter "norep" bewirkt, daß nicht versucht wird, eine Repository-Datenbank zu nutzen.
Hallo Welt Logging und Fehlerbehandlung
Am Beispiel des HalloWelt-Jobs wollen wir die Fehlerbehandlung erläutern: Jeder Schritt in einem Job kann einen Ausgabe- und einen Fehlerkanal ansteuern. Die Art des Sprungs kann variiert werden. Hier ein Beispiel:

Die Transformation "Hallo Welt Transf." kann einen Fehler enthalten. In diesem Fall wird eine Mail an den Schritt Mail->Mail versendet. Wir nennen diesen Schritt "Fehlermail". Der Schritt hat folgende Einstellungen:
- Im Reiter Addresses und Server geben Sie die Adreßdaten und dem SMTP-Server an.
- Im Reiter "EMail Message" können Sie Inhalt und Betreffzeile spezifizieren:

Wir wählen im Betreff "Kettle mail Fehler". Im Reiter "Attached Files" wählen wir die Logdatei vom Typ "Allgemein":

Man kann bei Dateityp auswählen auch mehrere Zeile markieren. Den normalen Logging-Kanal konfigurieren wir ebenfalls als Mail-Schritt. Dann produzieren wir einen Fehler in der Transformation, z.B. daß die Zieldatei nicht geschrieben werden kann. Wir erhalten folgende mail:

Projekt: Absolvent_innenlisten nach Fachbereich in Excel-Vorlagen schreiben
Das folgende Projekt an der Uni Wuppertal zeigt, wie man auf der Basis von HISinOne eine Absolvent_innenliste für ein bestimmtes Semester erzeugt. Kettle schreibt die Daten dabei in vorhandene Excel-Musterdateien. Diese werden dann nach Excel und PDF exportiert. Um die Schleifenfunktion zu demonstrieren, wird dann diese Liste noch einmal fakultätsweise erzeugt.
Aufbau Gesamtjob Absolvent_innenliste

Mit Semester als Parameter:

Transformation der Absolvent_innen
Hier die gesamte Transformation:

Absolvent_innenliste Selektion der Basisdaten
Wählen Sie einen "Table Input" Step:

Der Parameter ist das Semester. Hier der SQL zum Kopieren:
select C.orgunit_lid as fakultaet_nr,
PE.surname as nachname,
PE.firstname as vorname,
S.registrationnumber as mtknr,
C.degree_lid as abschluss_lid,
C.subject_lid as studiengang_lid,
E.date_of_work as abschlussdatum,
N.grade as Gesamtnote,
null::decimal as bewertungabschlussarbeit,
::varchar as titelabschlussarbeit,
::varchar as betreuerabschlussarbeit,
DP.studysemester as anzahlsemester,
::varchar as anschrift,
::varchar as plz,
::varchar as ort,
case when PE.k_gender_id=1 then 'Herr'
when PE.k_gender_id=2 then 'Frau'
else null::varchar(255) end as Anrede,
current_date as heute
from
hisinone.unit_studies US,
hisinone.course_of_study C,
hisinone.degree_program_progress DP,
hisinone.degree_program D,
hisinone.period P,
hisinone.student S,
hisinone.person PE,
hisinone.examplan E,
hisinone.term_type T,
hisinone.unit U ,
hisinone.examrelation R
left outer join hisinone.examresult N on (N.examrelation_id=R.id)
where U.id=US.unit_id
and C.lid=US.course_of_study_lid
and E.unit_id=U.id
and E.default_examrelation_id=R.id
and D.id=DP.degree_program_id
and DP.course_of_study_id=C.id
and DP.period_id=P.id
and D.student_id=S.id
and PE.id=S.person_id
and P.term_type_id=E.term_type_id
and P.term_year=E.term_year
and S.person_id=E.person_id
and T.id=E.term_type_id
and U.official_statistics =1 --Hauptprüfung
and (to_number(' ' || E.term_year || T.termnumber,'99999') ) = ${Semester}
order by 1,2,3;
Absolvent_innenliste Aufbereitung der Daten
Der Name des Abschlusses wird über einen Lookup Step geholt:

Man müßte hier noch weitere Lookups ausführen, z.B. für den Studiengangnamen, oder die Note der Abschlussarbeit. Danach wird die Ergebnisliste um nicht mehr benötigte Felder bereinigt:

Absolvent_innenliste Excel-Export
Im Excel Export wird eine Datei "Absolventenliste.xls" aus der "vorlage.xls" erzeugt:

Dabei werden die Basisdaten am Zelle A9 eingefügt:
Absolvent_innenliste PDF-Erzeugung
Kettle kann selbst kein PDF erzeugen, man kann aber mit OpenOffice bzw. Libreoffice über Kommandozeile PDF generieren. Dazu wählt man im Job den Step "Scripting" → "Shell". Hier das Beispiel für Linux:

Dies erzeugt die Kommandozeile:
/usr/sbin/soffice --headless --convert-to pdf Absolventenliste.xls
Absolvent_innenliste mit Schleife über Fakultäten
Aufbau Gesamtjob Absolventenliste mit Schleife
Der Gesamtjob ermittelt zuerst die Fakultäten, und erzeugt dann in einer Schleife je eine Absolventenliste in Excel. Diese werden dann auf einen Schlag nach PDF exportiert.

Fakultäten / Fachbereiche ermitteln
Die Fakultäten werden aus der Datenbank ermittelt:

Hier der SQL zum Kopieren:
SELECT O.lid as orgunit_lid,O.uniquename as fb_nr,O.defaulttext as fb_name from hisinone.orgunit O, hisinone.k_orgunittype K where K.id=O.k_orgunittype_id and K.hiskey_id=4 and current_date between O.valid_from and O.valid_to order by 2;
Absolvent_innenliste pro Fachbereich generieren
Die Fachbereiche werden zu Parametern kopiert, und die Transformation getAbsolventen wird in einer Schleife über jeden Fachbereich ausgeführt:

Die Transformation bekommt Parameter:

und der "Table Input"-Step wertet diesen aus:

Absolvent_innenliste Excel Export pro Fachbereich
Der Dateiname der Excel-Datei enthält jetzt auch den Fachbereichsschlüssel:

Die Fakultätsnummer wird im ersten Excel-Writer geschrieben:

Dann die Absolvent_innenliste. Die Transformation darf aber nicht gleichzeitig in die Excel-Datei schreiben. Dazu wird ein "Block until steps finish"-Step eingerichtet:

Der zweite Excel Writer ergänzt dann nur noch die Absolvent_innenliste:

PDF-Export pro Fakultäten
Da keine Wildcards unterstützt werden, müssen wir ein Shellscript erzeugen, z.B. für Linux:

Hier der Inhalt des Shellscriptes createpdf.x:
#!/bin/bash soffice --headless --convert-to pdf A*.xls
Das Ergebnis
Im Ergebnis erhalten wir eine Dateiliste mit n Absolvent_innenlisten jeweils in Excel und PDF:

Hier eine Vorschau in Excel:

und hier in PDF:

Projekt: Excel-Upload zur Anpassung von Daten in festgelegten Spalten
Im Folgenden wird erläutert wie Excel-Dateien genutzt werden um Datenbanktabellen zu manipulieren. Hierfür wird zunächst das Anwendungsbeispiel Stellenbewirtschaftungsbericht (STBB), welcher für das Land Sachsen entwickelt wurde, vorgestellt. Im Weiteren werden an diesem Beispiel, mit Blick auf die verwandte Software, diverse technische Details erläutert.
Anwendungsbeispiel
Die Werte der Spalte 4 (Soll lt. HHPL) sollen bei Bedarf durch Upload einer Excel-Datei (Excel-Template) angepasst werden können.
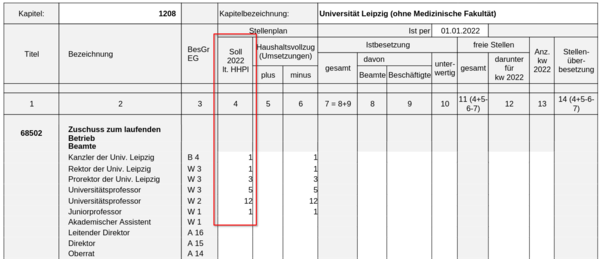

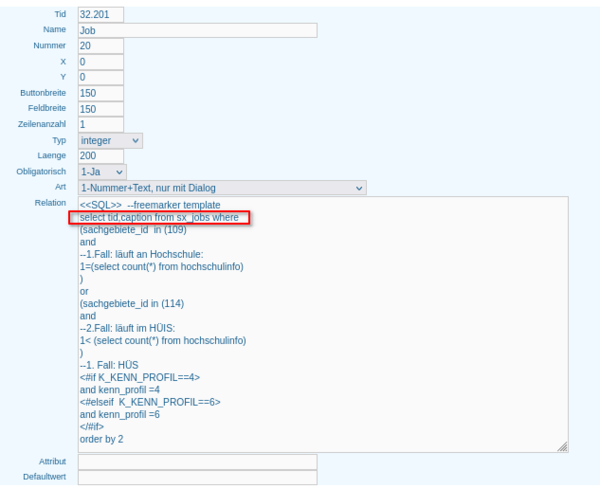
Die Datenbasis für die Spalte Soll lt. HHPL liefert die Tabelle kenn_stelle_hhpl, deren Inhalt über den Bericht "Stellen lt. HH-Plan" abgefragt wird.
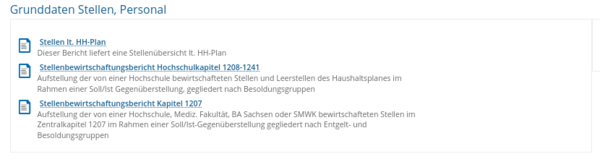

Die Maske bietet die Möglichkeit das sogenannte "Template für die manuelle Schnittstelle des STBB" als XSLX-Datei herunterzuladen.
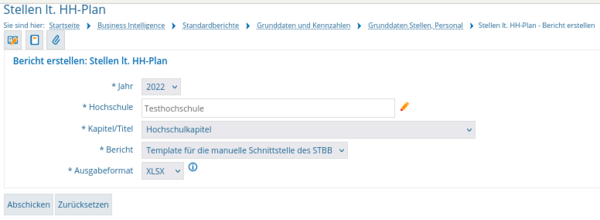

Das Template enthält alle Zeilen des Stellenbewirtschaftungsberichtes (STBB), sowohl diejenigen, welche mit Daten gefüllt sind, als auch jene, welche keine Daten enthalten.
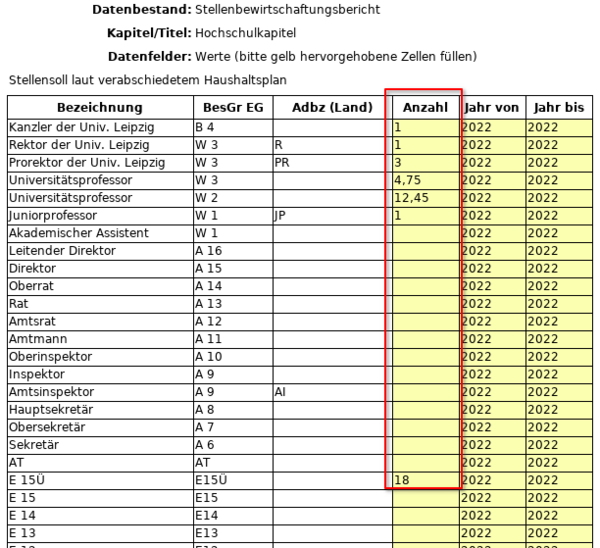

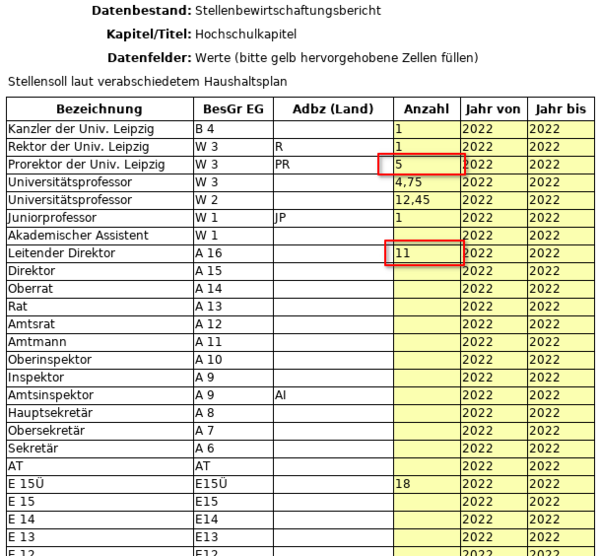
Im Template wird die Anzahl der Prorektoren auf 5 und die Anzahl der Leitenden Direktoren auf 11 erhöht. Das Template wird anschließend gespeichert.

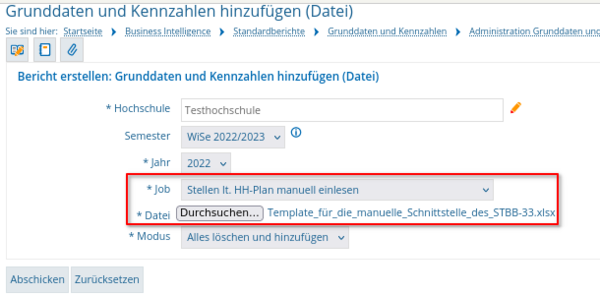
Um das Template hochzuladen wird der Bericht "Grunddaten und Kennzahlen hinzufügen (Datei)" genutzt. Es wird der Job "Stellen lt. HH-Plan manuell einlesen" ausgewählt, das Template angehängt und der Bericht abgeschickt.

Anschließend erscheinen die Änderungen im Stellenbewirtschaftungsbericht.
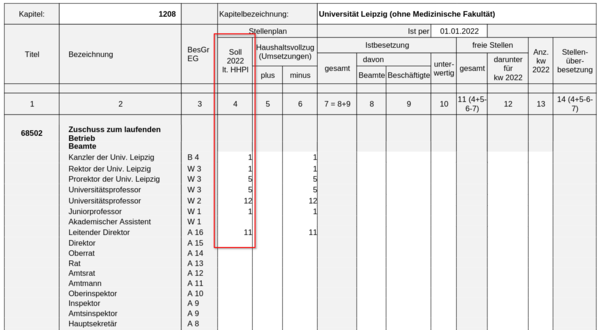

Den Ladejob mit Kettle erstellen
Der Ladejob wird mit Pentaho Data Integration (Kettle) erstellt. Im ersten Schritt "tmp_kenn_stelle_hhpl" wird per SQL eine temporäre Tabelle erstellt. Es folgen zwei Transformationsschritte (excel_into_tmp_kenn_stelle_hhpl und get_kapitel.ktr). Diese führen beide jeweils eine Transformation aus. Abschließend wird ein SQL-Skript ausgeführt (Update kenn_stelle_hhpl). Folgend wird der Transformationsschritt excel_into_tmp_kenn_stelle_hhpl näher betrachtet, welcher den Inhalt des Templates in die zuvor angelegte temporäre Tabelle schreibt.
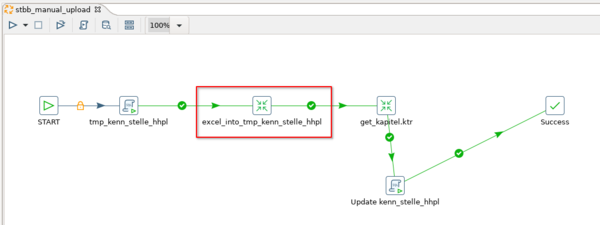

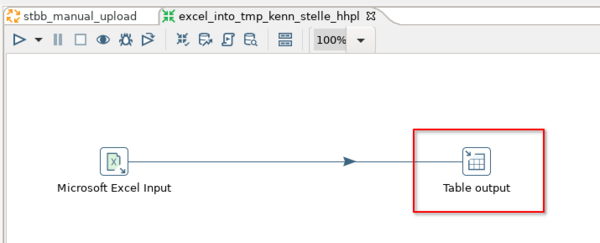
Die Transformation excel_into_tmp_kenn_stelle_hhpl besteht aus zwei Schritten. Dem "Microsoft Excel Input" und dem "Table output". Zunächst wird der "Microsoft Excel Input"-Schritt betrachtet.
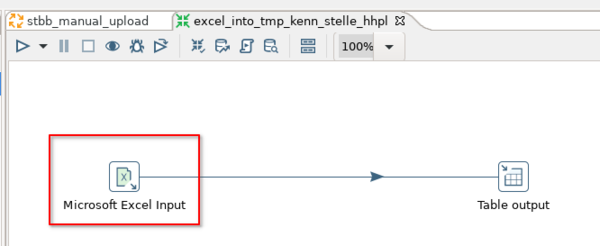

Im Reiter "Files" wird der Pfad zur Exceldatei angegeben. In diesem Falle handelt es sich um Die Variable ${PATH_TO_UPLOADFILE}, welche beim Abschicken der Maske "Grunddaten und Kennzahlen hinzufügen (Datei)" gefüllt wird.
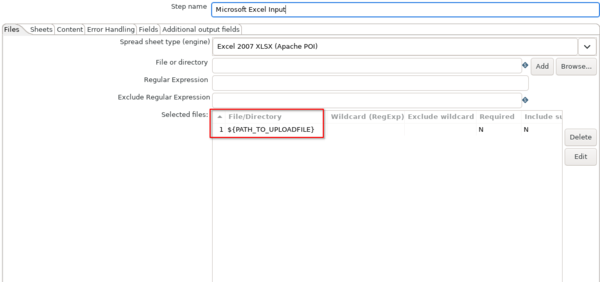

Um den Ladejob zum Test lokal ausführen zu können, wird die Variable mit einem Default gefüllt. Das geschieht unter "Edit-->Settings..." im Reiter "Parameters".
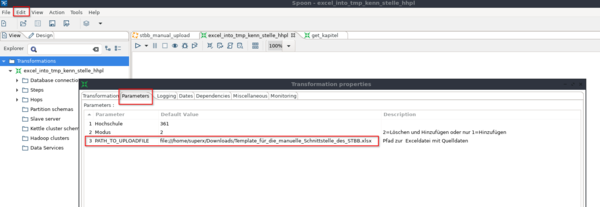

Im Reiter Sheets des "Microsoft Excel Input"-Schrittes wird der Name des Tabellenblattes der Excel-Datei angegeben, aus welchem gelesen wird. Dazu gehört eine Angabe der Zeile und Spalten, ab welcher Daten gelesen werden. Es wird bei 0 begonnen, das bedeutet in diesem Beispiel wird ab Zeile 6 und Spalte B ausgelesen.


Da im Beispieltemplate in Zeile 6 die Kopfzeile der Tabelle beginnt wird Header angeklickt, um zu signalisieren, dass die eingelesene Tabelle eine Kopfzeile enthält.
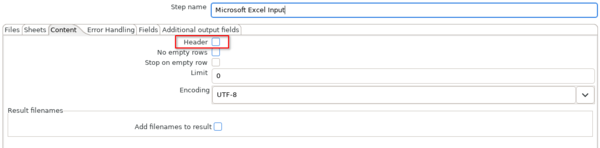

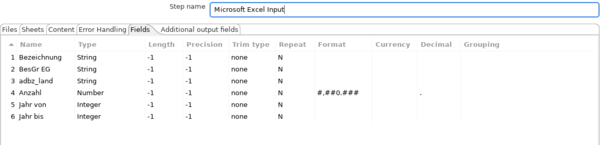
Im Reiter Fields werden die einzulesenden Spalten definiert. Wichtig ist, das bei führende 0-en (Nullen) auch bei Strings entfernt werden. Dies sollte bei Feldern, welche beispielsweise Schlüssel enthalten, unbedingt vermieden werden. Dazu wird unter Format für das jeweilige Feld eine Raute # eingetragen.

Im zweiten Schritt der Transformation wird der zuvor eingelesene Inhalt in eine Datenbanktabelle geschrieben.

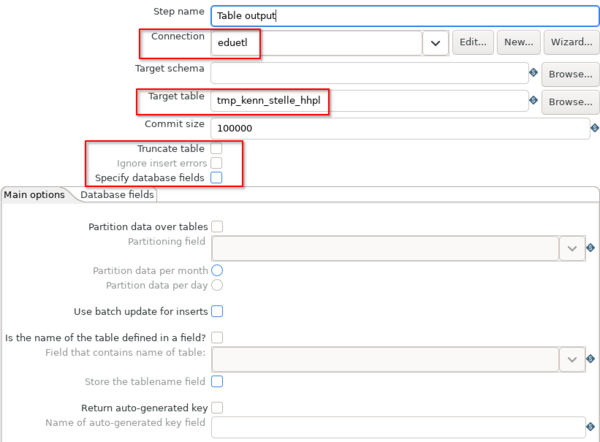
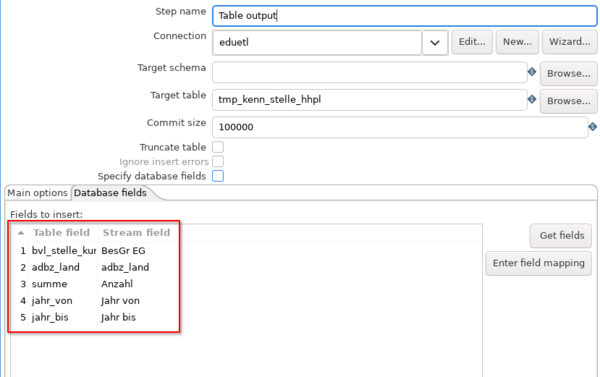
Wichtig ist die Connection eduetl zu nennen, damit der Ladejob auf den BI-Systemen läuft. Die Zieltabelle ist tmp_kenn_stelle_hhpl. Zudem kann beispielsweise ein Haken bei "Truncate Table" gesetzt werden, falls bei jedem Laden des Templates, die Zieltabell zunächst gelöscht werden soll. Um die Zielfelder der Zieltabelle näher zu definieren wird "Specify database fields" aktiviert und in den Reiter "Database fields" gewechselt.

Dort werden die Tabellenfelder ausgewählt und die dazugehörigen "Stream fields", aus welchen die Daten in die Tabellenfelder der Zieltabelle geschrieben werden. Bei den "Stream fields" handelt es sich um jene Felder, welche im "Microsoft Excel Input"-Schritt im Reiter fields benannt wurden.

Den Ladejob in das BI-System integrieren
Bevor der Job im System läuft, wird die Connection gelöscht. Hierzu ist der gesamte Tag sowohl im Job, als auch in den Transformationen zu löschen.
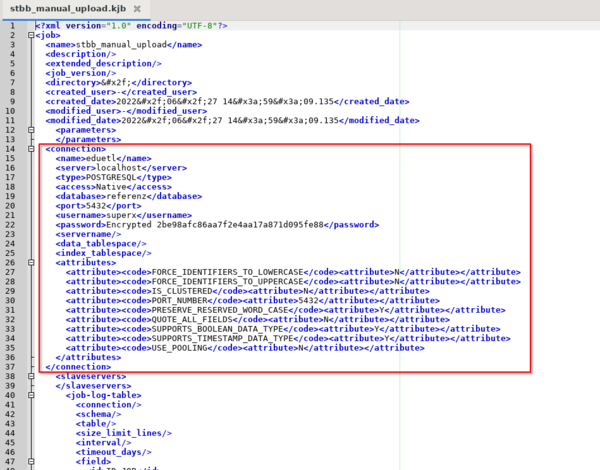

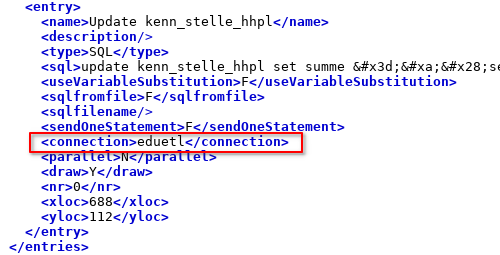
Die Connection-Information in den einzelnen Schritten bleibt jedoch enthalten.

Um den Job im System bekannt zu machen wird ein Eintrag in der Tabelle sx_jobs angelegt. Sie erreichen die Bearbeitung über das Menü Administration -> Tabelle suchen.
[[Bild:kettle_ladejobs1.png|400px]
Im Listenformular können Sie neue Jobs anlegen, oder vorhandene ändern.
[[Bild:kettle_ladejobs2.png|400px]
Hier unser Beispiel:
[[Bild:kettle_ladejobs3.png|400px]
Die Felder haben folgende Bedeutung:
Feld Beschreibung tid tid uniquename Unique Name caption Bezeichnung filepath Pfad zur Datei sachgebiete_id Sachgebiet kenn_profil Optional: Kenn-Profil hs_nr Optional: Hochschulnummer modus_supported Modus unterstützt? params optionale Parameter check_sql optionaler Prüf-SQL Für das Beispiel sieht der Datensatz wie folgt aus:
tid uniquename caption filepath ... check_sql 1450 nhs_stbb_hhpl_manuell Stellen lt. HH-Plan manuell einlesen kenn/etl/nhs_stbb_manuell/stbb_hhpl_manual_upload.kjb ... select count(*) from kenn_stelle_hhpl Das Ergebnis des Prüfprotokolls erscheint nach Ausführen des Jobs im Ladeprotokoll. Hier wird die Anzahl Datensätze in der Zieltabelle gezählt.
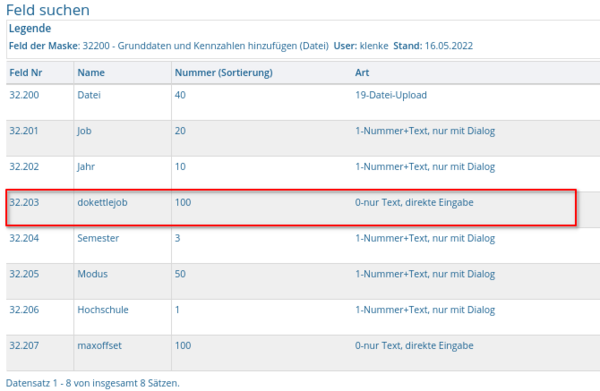
Die Masken, welche Ladejobs ausführen benötigen zwingend das Feld dokettlejob. Anhand dieses Feldes wird dem System mitgeteilt, dass ein Kettle-Job auszuführen ist. Das Feld darf versteckt werden.

Um die auswählbaren Kettle-Jobs zu definieren wird auf die Tabelle sx_jobs zugegriffen.