| Zeile 163: | Zeile 163: | ||
==BI Ladejob ausführen== | ==BI Ladejob ausführen== | ||
Vorab: Sie müssen die Umgebungsvariable CATALINA_OPTS erweitern: | |||
CATALINA_OPTS="... -DMODULE_PFAD=/var/lib/tomcat9/webapps/superx/WEB-INF/conf/edustore/db/module ..." | |||
Unter Ubuntu liegt das in der Datei | |||
/etc/default/tomcat9 | |||
dort die Variable | |||
JAVA_OPTS="... -DMODULE_PFAD=/var/lib/tomcat9/webapps/superx/WEB-INF/conf/edustore/db/module ..." | |||
Danach muss man Tomcat neu starten. | |||
Um den Job im System bekannt zu machen wird ein Eintrag in der eduetl-Tabelle ''sx_jobs'' angelegt. | Um den Job im System bekannt zu machen wird ein Eintrag in der eduetl-Tabelle ''sx_jobs'' angelegt. | ||
Version vom 5. Dezember 2022, 08:39 Uhr
Monitoring/Logging von Kettle Jobs
Mailversand in Kettle
Mailversand Beispiel 1
Unser erster Beispieljob versendet einfach nur eine Mail. Hier eine Gesamtübersicht der Schritte im Job:

Der Job führt nur einen Dummp-Step aus, und verschickt dann eine Mail. Dazu gibt es im Reiter "Design" einen Step:

In dem Dialog im Reiter "Adresses" spezifizieren Sie die Absender- und Empfängeradresse. Danach geben Sie Daten zum Mailserver an:

Unser Beispiel-Mailserver verlangs Zugangsdaten zum Mailversand, diese tippen wir einfach ein. Danach wird Betreff und Inhalt der Mail definiert:

Wir versenden eine einfache Testmail mit voreingestellten Kettle-Protokolldaten. Dann starten wir den Job:

Der Job war erfolgreich, und es müßte tatsächlich eine Mail ankommen:

Damit haben wir ein einfaches Beispiel zum Mailversand abgeschlossen.
Mailversand mit Variablen
Im obigen Beispiel haben wir die Angaben zum Mailversand "hartcodiert" in den Dialog eingetragen. Da es vermutlich mehrere Jobs mit Mailversand gibt, ist es sinnvoll die immer wiederkehrenden Angaben zum Mailserver etc. in Variablen auszulagern. Wir verfeinern also obiges Beispiel, indem wir dem Mailversand eine Transformation vorschalten, die die Variablen definiert und setzt. Hier eine Gesamtübersicht des Jobs:

Da in der Regel solche Angaben in einer Datenbank vorgehalten werden, wählen wir in der Transformation einen Table-Input Step:

Der Step selektiert die jew. Parameter, das Beispiel funktioniert unter Postgres und kann so leicht auf die eigene DB angepaßt werden.

Die Parameter werden dann über den "Set Variables"-Step zur Laufzeit im gesamten Job zur Verfügung gestellt:

Der folgende Dialog zum Mailversand wir dann statt "hartcodiert" mit Verweisen auf die Variablen versehen:

Im folgenden Reiter zum Mailserver sind die Angaben dann analog vorzunehmen. Der Job sollte danach genauso funktionieren wie das erste Beispiel.
Mailversand mit ausgelagerten Variablen
Im obigen Beispiel haben wir "sensitive" Angaben zum Mailversand (Benutzername, Passwort) "hartcodiert" in die Datenbank geschrieben. Hier ist es sinnvoll, diese Angaben aus Job und Datenbank herauszunehmen. Kettle bietet die Möglichkeit, zentrale bzw. systemspezifische Variablen in eine Datei "kettle.properties" auszulagern, Details dazu siehe unten.

Das verschlüsselte Passwort und die Zugangskennung wird dann als Variable übergeben.

Das Passwort-Feld ist maskiert, die Eingabe ist
${MAILPW}
| Bei einer Änderung der kettle.properties müssen Sie Spoon neu starten. |
Loglevel und -dateien
Kettle bietet diverse Möglichkeiten zum Logging und zur Fehlerbehandlung:
- Logausgabe von Spoon / Kitchen
- In Jobs kann man diese verfeinern mit dem "Write to log"-Step
- Eine Transformation kann
- die Logausgabe in einer dezidierten Logdatei speichern bzw. erweitern
- im Aufruf eines Jobs in eine Fehlerbehandlung laufen
Das folgende Beispiel zeigt die Nutzung, im Job wird eine Logdatei angelegt, und dann schreiben die einzelnen Transformationen in diese Logdatei. Diese wird dann am Ende per Mail als Anhang verschickt - egal ob es mit Fehler oder erfolgreich war:

Im ersten Schritt wird die Logdatei "ladejob.log" angelegt bzw. geleert, wenn sie schon existiert:

Die erste "Set variables"-Transformation wird im Reiter "Logging" so konfiguriert, dass die Ausgabe in die Logdatei "ladejob.log" geloggt wird.

Ergänzend wollen wir auch die gesamt-Logausgabe des Jobs um eine Zeile erweitern, die die übergebene Mailkennung aus der kettle.properties ausgibt:

Danach wird eine Transformation erstellt, die Postgres-spezifische Systemvariablen
- selektiert und
- das Ergebnis in die Logdatei schreibt

Da diese Operation aus der Datenbank liest und ggf. Fehler bewirken kann, wird neben der normalen Erfolgs-Ausgabe ein "Fehlerkanal" eingerichtet, der eine entsprechende Fehler-Mail verschickt:

Im Reiter "Attached files" wird die Logausgabe des Jobs angehängt:

Unser Job arbeitet von nun an mit einer Fehler- und Logbehandlung.
Versionierung von Jobs
- Kettle Jobs und git-Versionierung
Entfernen der Connection-Elemente
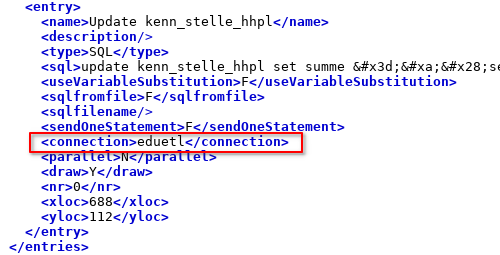
Beim Speichern eines Jobs wird immer die Connection mitgespeichert. Daher muss sie vor dem Commit ins git gelöscht werden. Hierzu ist der gesamte Tag sowohl im Job, als auch in den Transformationen zu löschen.
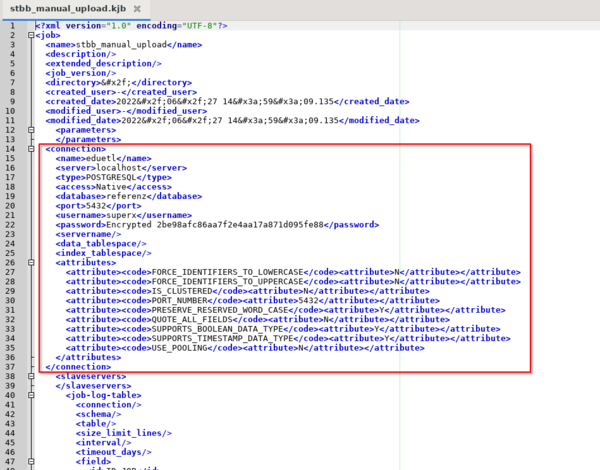

Die Connection-Information in den einzelnen Schritten bleibt jedoch enthalten.

Jobmanagement
Im folgenden zeigen wir wie Sie Jobs "on demand" direkt aus HISinOne oder SuperX im Browser vom Nutzer starten lassen.
Eigenes BI-Modul
Ein Kettle Job ohne Eingabeparameter kann in einem eigenen "Mini"-Modul deklariert und über das HISinOne-Jobmanagement ausgeführt werden.
- Erstellen Sie ein minimales Modul mit einer Modul-XML-Datei
- In der Modul-XML-Datei im Bereich ETL können Sie Ladejobs deklarieren
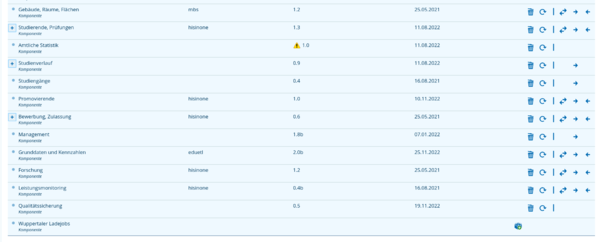
- Das Modul können Sie auf eine SuperX- oder BI-Installation synchronisieren oder die zip-Datei dort unter $SUPERX_DIR bzw. webapps/superx entpacken
- Danach ist es in der BI-Komponentenverwaltung sichtbar:
Mit Klick auf das "Installations-"Icon wird es installiert
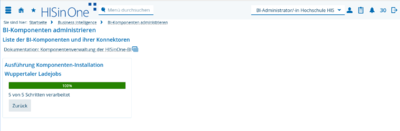
und danach ist es auch in der Konnektorenübersicht sichtbar, inkl. Unter-Ladejobs:

Die Jobs können dann über das BI Jobmanagement ausgeführt werden. Auch ein zeitgesteuertes Ausführen ist möglich , per Kommandozeile.Über die Browser-Oberfläche ist ebenfalls ein zeitgesteuerter Update möglich. Gehen Sie dazu in die Admin-Rolle, und wählen das Menü Administration -> Konfigurationsassistenten:
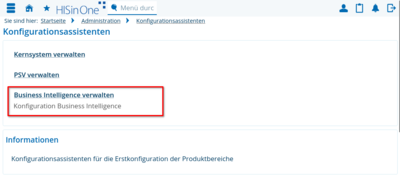
Ajuf dem Reiter "Business Intelligence" können Sie den jew. Job markieren und so in die nächtliche Laderoutine aufnehmen:
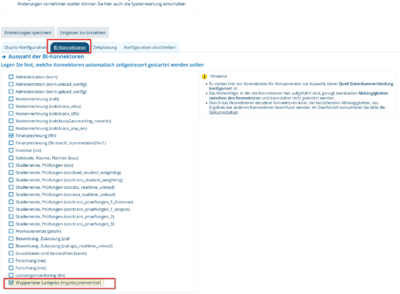
Weitere Details siehe die Beschreibung des Installationsassistenten bei HIS.
BI Ladejob ausführen
Vorab: Sie müssen die Umgebungsvariable CATALINA_OPTS erweitern: CATALINA_OPTS="... -DMODULE_PFAD=/var/lib/tomcat9/webapps/superx/WEB-INF/conf/edustore/db/module ..." Unter Ubuntu liegt das in der Datei /etc/default/tomcat9 dort die Variable JAVA_OPTS="... -DMODULE_PFAD=/var/lib/tomcat9/webapps/superx/WEB-INF/conf/edustore/db/module ..." Danach muss man Tomcat neu starten.
Um den Job im System bekannt zu machen wird ein Eintrag in der eduetl-Tabelle sx_jobs angelegt.
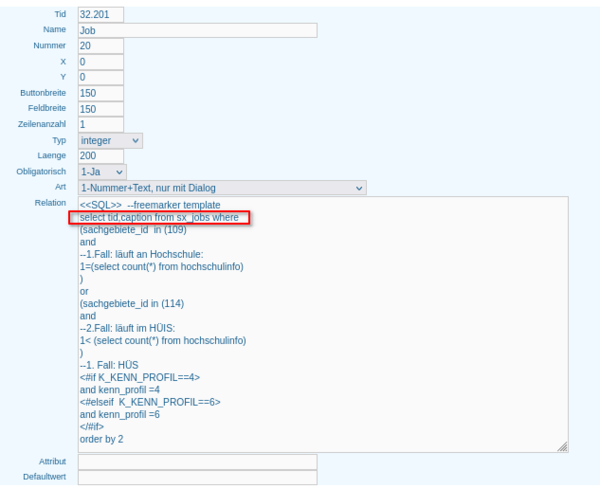
Feld Beschreibung tid tid uniquename Unique Name caption Bezeichnung filepath Pfad zur Datei sachgebiete_id Sachgebiet kenn_profil Optional: Kenn-Profil hs_nr Optional: Hochschulnummer modus_supported Modus unterstützt? params optionale Parameter check_sql optionaler Prüf-SQL Ein Beispiel - Datensatz sieht wie folgt aus:
tid uniquename caption filepath ... check_sql 1450 nhs_stbb_hhpl_manuell Stellen lt. HH-Plan manuell einlesen kenn/etl/nhs_stbb_manuell/stbb_hhpl_manual_upload.kjb ... select count(*) from kenn_stelle_hhpl Das Ergebnis des Prüfprotokolls erscheint nach Ausführen des Jobs im Ladeprotokoll. Hier wird die Anzahl Datensätze in der Zieltabelle gezählt.





Die Masken, welche Ladejobs ausführen benötigen zwingend das Feld dokettlejob. Anhand dieses Feldes wird dem System mitgeteilt, dass ein Kettle-Job auszuführen ist. Das Feld darf versteckt werden.
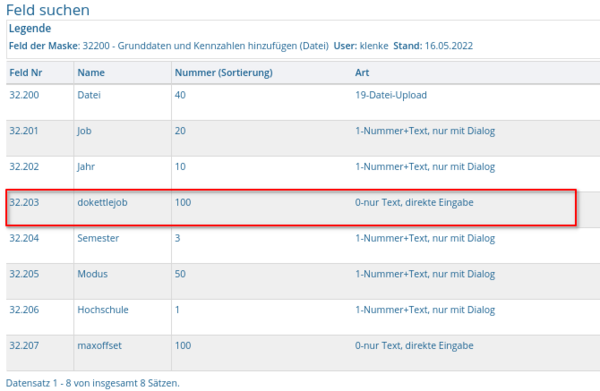

Um die auswählbaren Kettle-Jobs zu definieren wird auf die Tabelle sx_jobs zugegriffen.

Kitchen
Kitchen dient der Ausführung von Kettle Jobs via Kommandozeile. Wichtig ist die Umgebung, in der Kitchen gestartet wird.
Home-Verzeichnis
Zunächst ist es wichtig, das Home-Verzeichnis von Kettle beim Aufruf von Kitchen zu kennen. Standardmäßig liegt das Verzeichnis in HOME/.kettle, also unter Linux (3 Varianten):
$HOME/.kettle ~/.kettle /home/Benutzername/.kettle
und unter Windows ( 2 Varianten):
C:\users\Benutzername
C:\Documents and Settings\{Benutzername}\.kettle
Im Home-Verzeichnis von Kettle werden Konfigurationsdateien gesucht. Sie können das Home-Verzeichnis auch variiieren, indem Sie die System-Umgebungsvariable KETTLE_HOME setzen.
Umgebungsvariablen
Im Home-Verzeichnis wird nach zwei Dateien gesucht:
- kettle.properties
- Allgemeine Umgebungsvariablen
- shared.xml
- Datenbankverbindungen
Kettle.properties
Sie können in der Textdatei beliebige Konfigurationen setzen, die Sie nicht in den Jobs / Transformationen oder in der Datenbank speichern wollen, z.B. Zugangsdaten für Email-Server. Beispielinhalt:
MAILUSER = schulung@superx-projekt.de MAILPW = anfang12
Sie können Passworte sogar verschlüsseln, indem Sie das Kommandozeilen-Tool "encr" nutzen. Unter Linux:
encr.sh -kettle anfang12
Unter Windows:
encr.bat -kettle anfang12
| Wenn Ihr Passwort Leerzeichen oder Sonderzeichen enthält, ist es sicherer das Passwort mit einfachem Hochkomma (Linux) oder doppelten Anführungsstrichen (Windows) zu umschließen. |
Es wird ein verschlüsseltes Passwort ausgegeben:
Encrypted 2be98afc86aa7f2e4aa17a871d095fe88
Dieses Passwort können Sie dann in die kettle.properties eintragen:
MAILUSER = schulung@superx-projekt.de MAILPW =Encrypted 2be98afc86aa7f2e4aa17a871d095fe88
Speziell für Datenbankverbindungen gibt es eine eigene Datei. Hier ein Beispiel:
<?xml version="1.0" encoding="UTF-8"?>
<sharedobjects>
<connection>
<name>eduetl</name>
<server>localhost</server>
<type>POSTGRESQL</type>
<access>Native</access>
<database>superx</database>
<port>5432</port>
<username>superx</username>
<password>Encrypted 2be98afc86aa7f2e4aa17a871d095fe88</password>
<servername></servername>
<data_tablespace/>
<index_tablespace/>
<attributes>
<attribute>PORT_NUMBER<attribute>5432</attribute></attribute>
</attributes>
</connection>
<connection>
<name>hisinone</name>
<server>localhost</server>
<type>POSTGRESQL</type>
<access>Native</access>
<database>hisinone_cust</database>
<port>5432</port>
<username/>
<password>Encrypted 2be98afc86aa7f2e4aa17a871d095fe88</password>
<servername/>
<data_tablespace/>
<index_tablespace/>
<attributes>
<attribute>PORT_NUMBER<attribute>5432</attribute></attribute>
</attributes>
</connection>
</sharedobjects>
Es werden zwei Datenbankverbindungen konfiguriert, die dann in Kettle Transformationen im Element "connection" genutzt werden können.
| Bei der Entwicklung von Jobs und Transformationen werden die Connection-Elemente auch in den jew. Quelltext geschrieben und gespeichert. Und bei der Ausführung haben diese Elemente eine höherer Priorität als die shared.xml, so dass man diese Elemente vor dem Installieren im Zielsystem entfernen muss. |
Kettle Goodies
- Coole neue Features